When we give images to an LLM, e.g., ChatGPT, Gemini, Claude, Deepseek, etc., and ask something about that image with a prompt, do you know what happens inside the magical box?
LLMs like text-only GPT4 or below, like GPT3, cannot read images directly. Instead, they use another type of language model called VLM - Vision Language Model. Nowadays, various VLMs are used alongside LLMs to understand images and generate high-quality captions. e.g., CLIP developed by the OpenAI team, BLIP developed by Salesforce Research, Flamingo developed by the DeepMind team, and so on.
VLM-Vision Language Model
is same type of model as like LLM which are builded on Transformer Architecture. VLM is trained on large amount of Image Text Pairs datasets such as LAION-5B- which contains 5 Billion Image Text pairs collected from the internet by scraping, YFCC100M- a dataset of 100 Million images from Flickr, WIT-400M- a dataset of 400 Million Image Text Pairs taken from Wikipedia, COYO-700M- a dataset of 700 Million high quality web crawled Image Text pairs. VLM also trained on pathological datasets also such as PathCap: (~207k pairs) - from academic sources, OpenPath: (~208k image text pairs) - from Twitter posts, QUILT: (~769k image text pairs) - from YouTube videos.
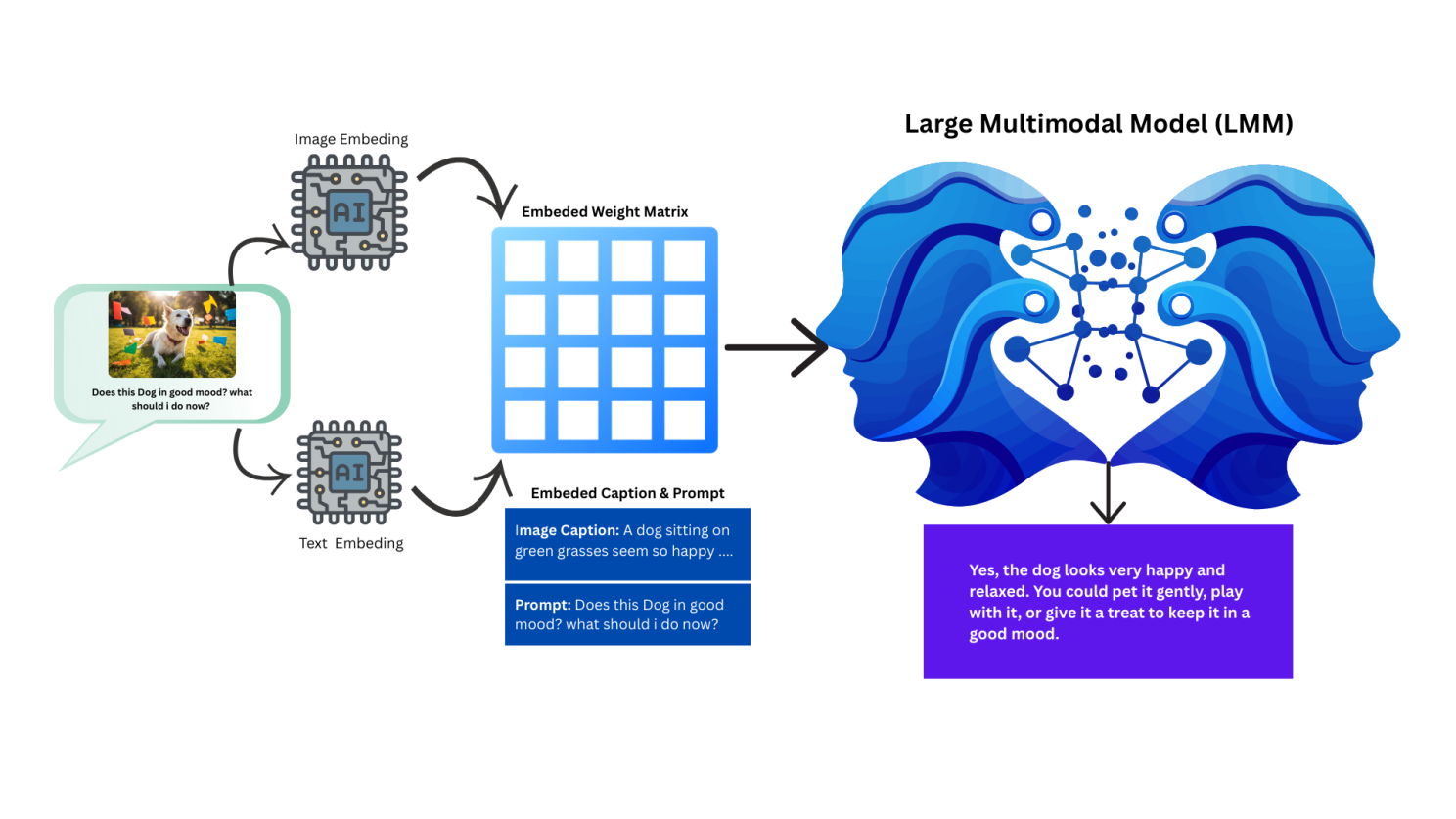
So when we give images to the input along with a prompt, the image goes through the VLM first. VLM generates the captions from the given image and then the caption along with prompt passed to the LLM, then LLM proceed the generate it's token (response) and you get surprised. Below's diagram is illustrating the whole flow.
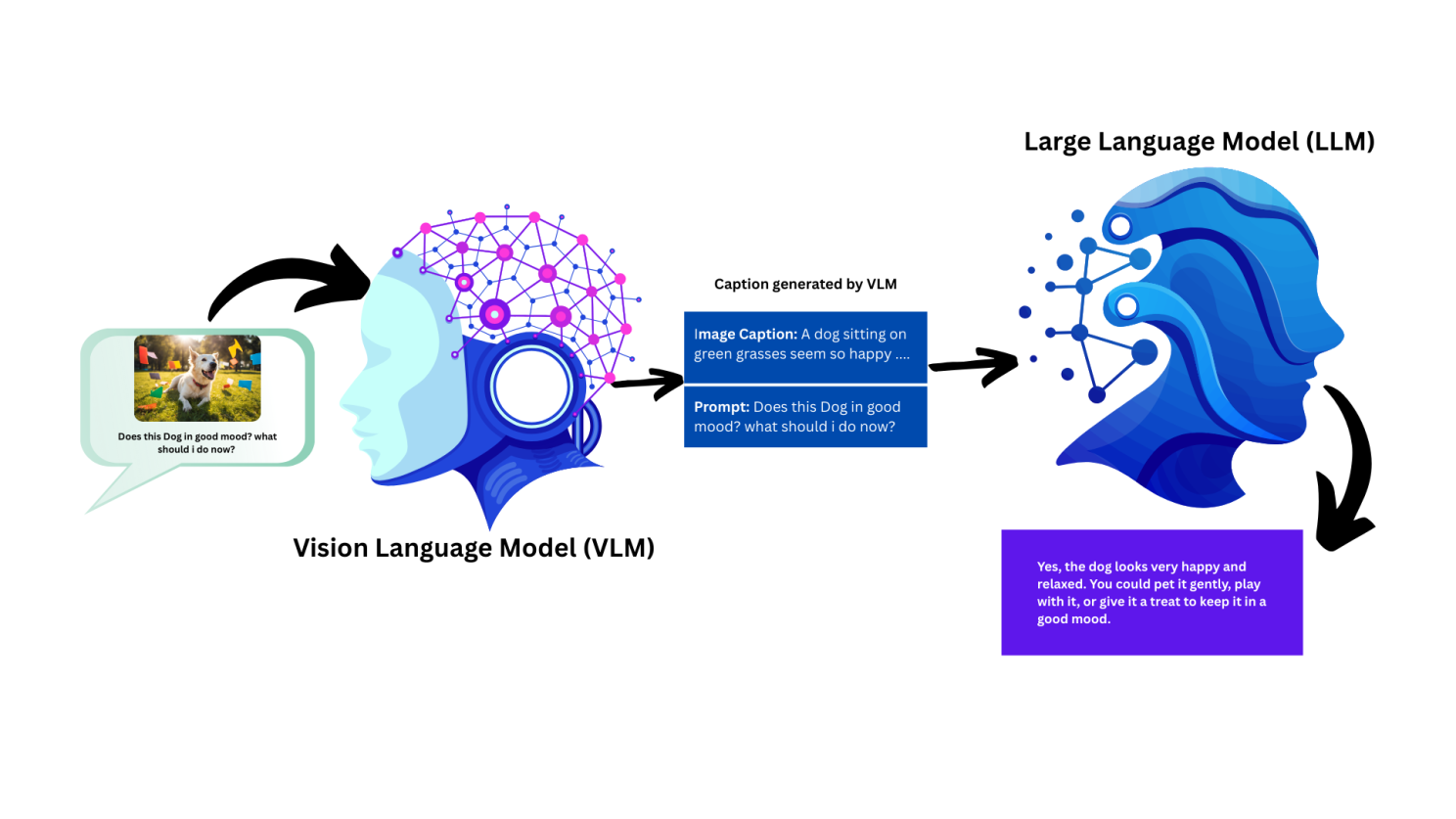
vlm with llm
LMM Large Multimodal Model
What if we had a single model which can understand both image and text all alone itself. It doesn't required VLM to understand image and LLM to understand text independently. This type of model is called LMM Large Multimodal Model. Hence the LMM model is a single box of Transformer which can do Vision type task along with text prompts. Almost all the modern models like GPT5, GPT4V and so on act like LMM when we provide it images with prompt otherwise it treat as LLM.
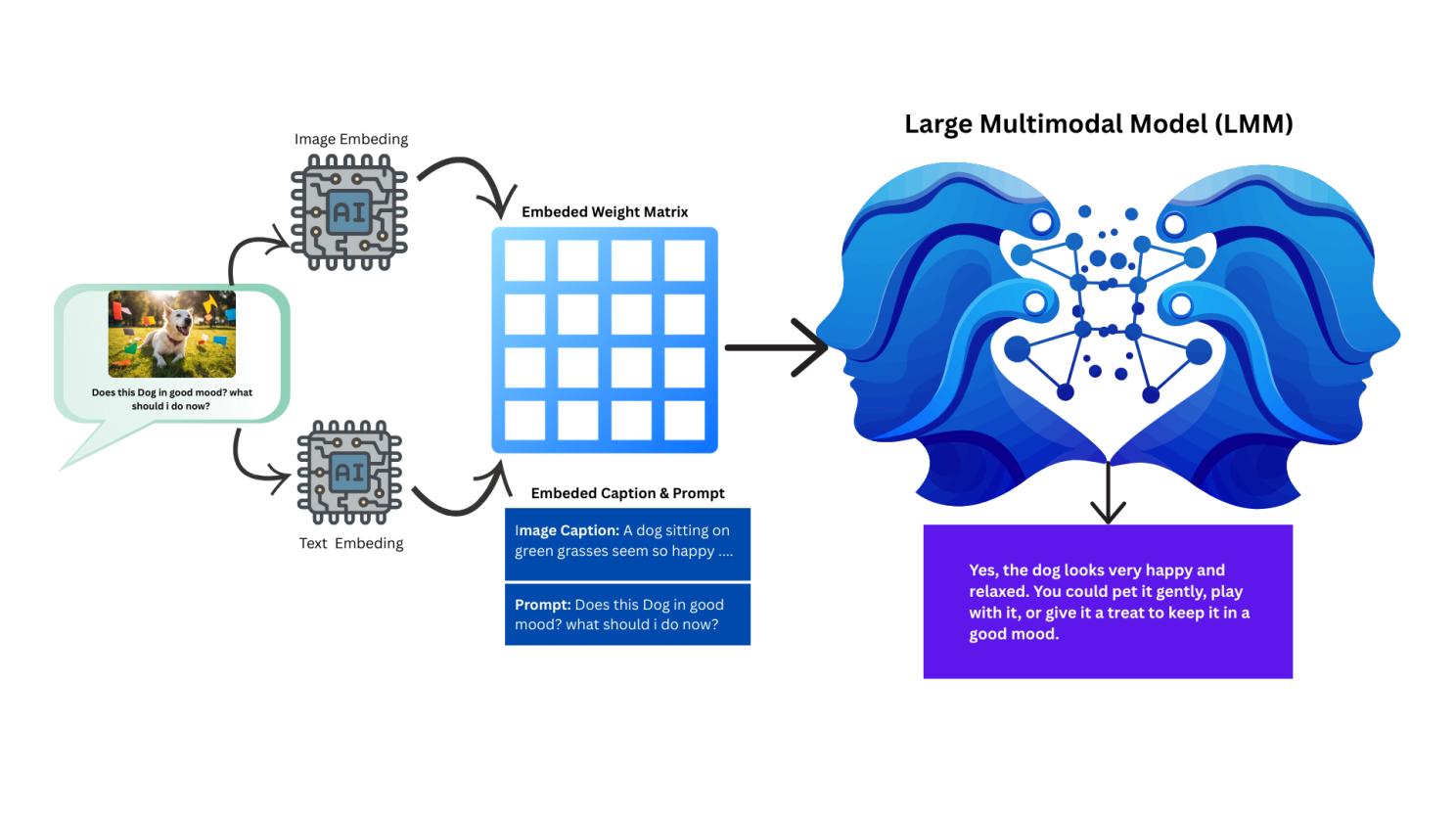
LMM
Behind the scene, researchers are trying to build some better embeddings that is closer to both image & text so that a single model can do all like LMM. The Transformer architecture initially developed by Google is the backbone of these generative AI Models.